
在一场科技与音乐结合的Liveshow中,8月31日,AI独角兽企业MiniMax上海稀宇科技有限公司(以下简称MiniMax)第一届开发者大会——“MiniMaxLink伙伴日”拉开帷幕。当日伙伴日现场,MiniMax正式发布视频模型—video-01以及音乐模型music-01。
布局多模态模型只是一个开始
多模态模型已经成为大模型企业的必答题,其中以视频模型内卷最为明显,已经有多家AI企业早先发布了大模型视频,包括智谱AI推出的视频生成模型“清影”、爱诗科技的PixVerse V2、生数科技的Vidu,快手的“可灵AI”等。
据了解,MiniMax此次发布的video-01主打原生高分辨率高帧率视频生成,输入提示词可生成五秒钟视频时长,用户可登录MiniMax官网体验该产品。

MiniMax正式发布视频模型—video-01
有产品设计师测评视频模型video-01后认为,“整体效果非常不错,物理正确、动态幅度以及稳定性都不错,对科幻以及奇幻概念响应也相对准确,但是塑料感很重。美学表现相对差,画质和画面细节差一些。”
对此,Minimax创始人兼首席执行官闫俊杰表示,目前对外展示的只是产品的初版,未来会逐步推出更新版本。
也是基于这个原因,该视频模型将会先免费提供给用户使用一段时间,直到产品更新到满意的状态,才会考虑商业化。“未来的商业化主要分为两种形式,一类是基于公司的开放平台,以及公司积累的2000多家客户合作伙伴,很多知名公司用户也愿意使用声音识别能力,另一类则计划在自有产品中引入广告机制。”
据介绍,MiniMax当下的多模态模型矩阵产品还包括music-01多功能端到端音乐生成大模型、speech-01新一代生成式语音合成大模型等。“这只是一个开始,接下来将在模型速度和效果方面继续改进,将会进一步发布相应产品。”闫俊杰表示。
MiniMax一直致力于基础模型的研发工作,为何会开始加入视频生成赛道,布局多模态模型?
闫俊杰认为,MiniMax进入视频生成领域是非常自然的过程。当前,用户消费的主要内容形式已经从文字转向了动态内容,这是非常重要的领域。虽然文本模型是信息的精华部分,但为了更好地覆盖、触达用户,必须涉足动态内容。因此,MiniMax的技术路线,逐步从文字开始拓展至声音、图片,现在是视频。
提升模型性能的关键
“作为一家科技公司,技术始终是最核心的要素。”闫俊杰说,现阶段MiniMax关注的主要重点并不是商业化。
闫俊杰介绍说,目前MiniMax的模型处理着超过30亿次的客户交互。一年之前,MiniMax交互时长仅为ChatGPT的3%;现在这一比例已提升至53%;但即便如此,连接的用户还没有达到全球人口的 1%,只有是 0.8%。要从1%增⻓到100%,最重要的是提高AI产品在用户中的渗透率和使用深度。
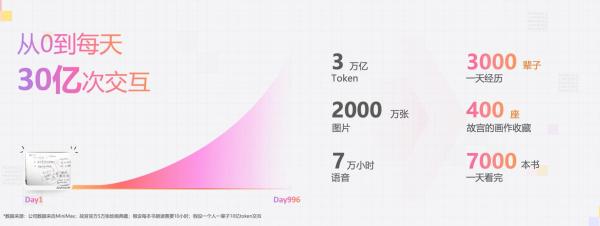
MiniMax用户交互数据
这其中很多技术难关需要攻克,其中最重要的三个优化方向是:如何让模型的错误率持续降低,无限⻓的输入和输出,以及多模态。“从生活中不难发现,文字交互只是很小的一部分,更多的是语音和视频交互。多模态的内容,比如声音,图文和视频,已经成为信息传递的主流。为了能够提高渗透率,多模态就是必经之路。”闫俊杰说,要攻克这些难关,“快”是MiniMax底层大模型的核心技术研发目标。“在两个性能类似的模型中, 训练和推理更快的那个,可以更有效地利用算力资源迭代更多的数据,从而能够有一个更好的模型能力。”
据介绍,MiniMax在过往经历了两次关键的底层技术变革,包括MOE(混合专家架构)和Linear Attention(线性注意力)。今年4月,该公司研发出的新一代基于MOE+ Linear Attention 的模型,被视为可以比肩GPT-4o的水平。在处理10万token时,新模型的处理效率可提升达2-3倍,并且随着⻓度越⻓,模型效率提升越明显。
据了解,采用新一代技术的abab7系列文本模型将于未来数周内正式发布。
公开报道显示,成立于2021年12月的MiniMax 此前已完成3轮融资,投资方包括腾讯、米哈游等,当前估值已经超过25亿美元。




还没有评论,来说两句吧...